Discovery
Overview
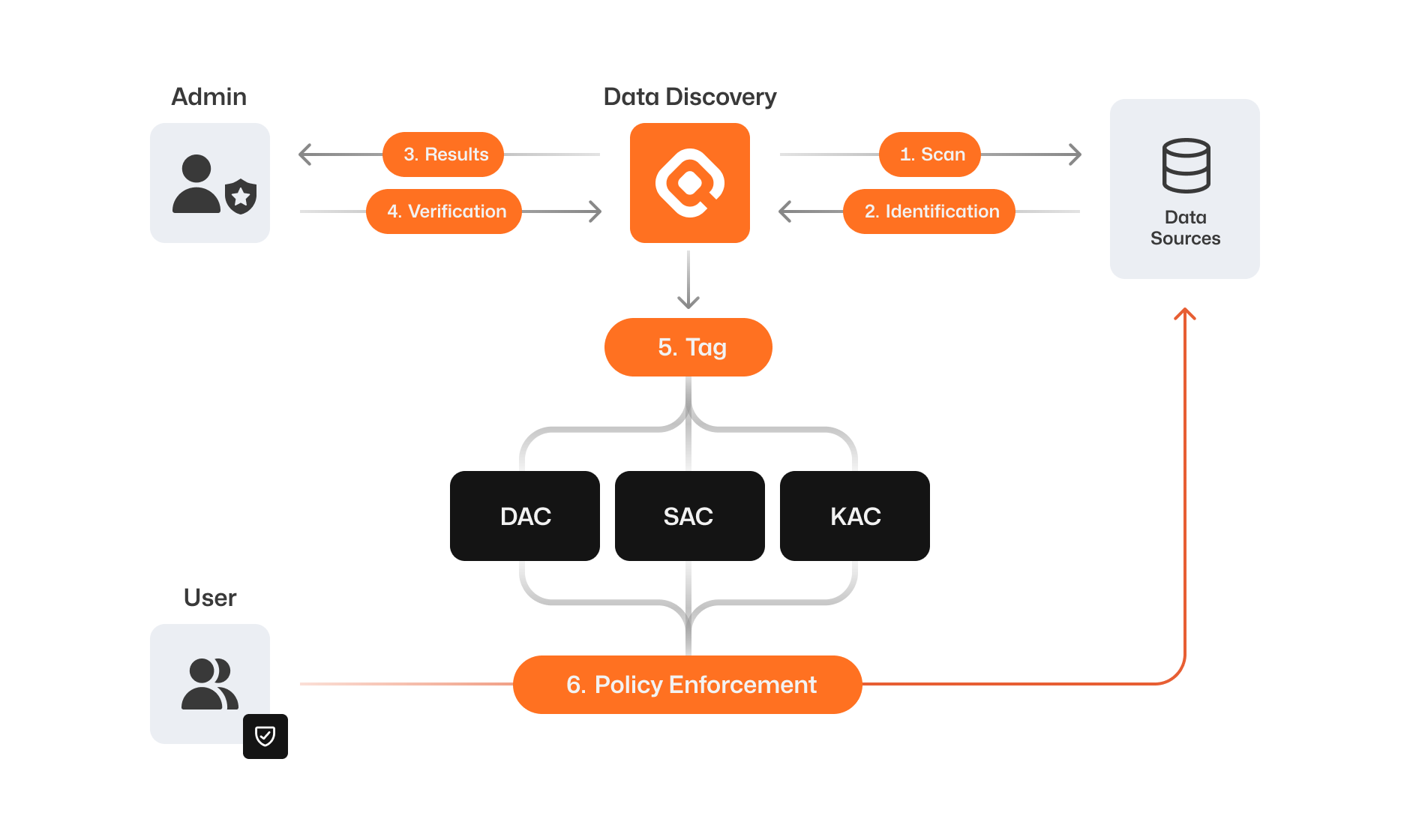
How AIDD Works
조직의 성장에 따라 생산하고 사용하는 데이터의 규모가 커지고 종류도 다양하게 됩니다. 이는 관리에 큰 부담으로 작용할 수 있습니다. 복잡하고 다양한 조직내 데이터 소스에 대해, 다양한 경로로 생성되거나 유입된 민감정보의 존재를 식별하는 것은 보안 관점에서 상당한 중요성을 가지게 됩니다. 따라서 조직내의 민감정보는 아래와 같이 관리되어야 합니다.
조직내의 민감정보 식별 : 먼저 관리자는 조직내에 어떤 유형의 민감정보가 존재하는지 인식해야 합니다.
자동 식별 : 관리자가 각각의 데이터 소스에 접근하여 수동으로 식별작업을 수행하는 것이 아니라 자동으로 식별이 수행되어야 합니다.
규칙적인 관리 : 조직의 데이터는 역동적으로 변화하므로 정해진 주기로 지속적인 확인이 필요합니다.
관련된 유형과 컴플라이언스 매핑 : 발견된 민감정보는 민감정보의 유형별로 구분되고 연관된 규제를 쉽게 확인할 수 있어야 합니다. 이를 토대로 발견된 민감정보에 대해 어떤 방법으로 보호할지 계획할 수 있습니다.
발견된 민감정보에 대한 접근통제 : 발견된 민감정보는 반드시 접근하는 대상이 통제되어야 하고 마스킹 또는 암호화 등 필요한 보안조치가 이뤄져야 합니다.
주기적인 감사와 모니터링 : 민감정보가 어떻게 소비되고 있는지 주기적인 감사와 모니터링을 통해 다양한 보안 위협에 대응하는 새로운 전략을 세울 수 있습니다.
QueryPie Data Discovery를 통해 관리되는 민감정보
QueryPie의 Data discovery는 조직내 데이터 소스에 대해, 주기적으로 또는 사용자가 원하는 시점에 수동으로 탐색을 수행합니다.
존재하는 민감정보를 자동으로 식별하여 분류된 태그를 부여합니다.
식별된 민감정보는 민감정보의 유형별, 연관된 규제에 자동 매핑되어 쉽게 확인할 수 있습니다.
관리자는 탐색의 결과로 자동 감지된 민감정보의 오탐지 유무를 판단하고 해당 데이터 소스의 민감정보의 존재를 확정합니다.
관리자를 통해 확인된 민감정보는 존재하는 경로에 태그의 형태로 부여되어 최종적으로 inventory에 반영됩니다.
위와 같이 최종적으로 확정된 민감정보에 대한 내용을 대시보드를 통해 쉽게 식별이 가능합니다.
일반적인 데이터 디스커버리와 보안 데이터 디스커버리의 차이점
목적
일반적인 데이터 디스커버리는 데이터 분석을 통해 비지니스 인사이트를 도출하고 의사결정에 도움을 주는 것을 목표로 합니다.
보안 데이터 디스커버리는 데이터를 보호하고 보안위협을 예방하며 규제 준수를 보장하는데 중점을 둡니다.
분류기준
일반적인 데이터 디스커버리는 분석 용이성이나 비지니스 목적에 따라 데이터를 분류합니다.
보안 데이터 디스커버리는 데이터를 민감도와 보안 필요성에 따라 분류합니다.
사용 기술
일반 데이터 디스커버리는 주로 데이터 분석 도구와 시각화 도구를 사용합니다.
보안 데이터 디스커버리는 데이터 분류 도구, 데이터 손실 방지(DLP) 솔루션, 데이터 접근 제어 시스템 등을 사용합니다.
결과 활용
일반 데이터 디스커버리의 결과는 비즈니스 전략 수립, 마케팅, 운영 최적화 등에 활용됩니다.
보안 데이터 디스커버리의 결과는 보안 정책 강화, 위협 대응, 데이터 보호 조치 등에 활용됩니다.