Discovery
Overview
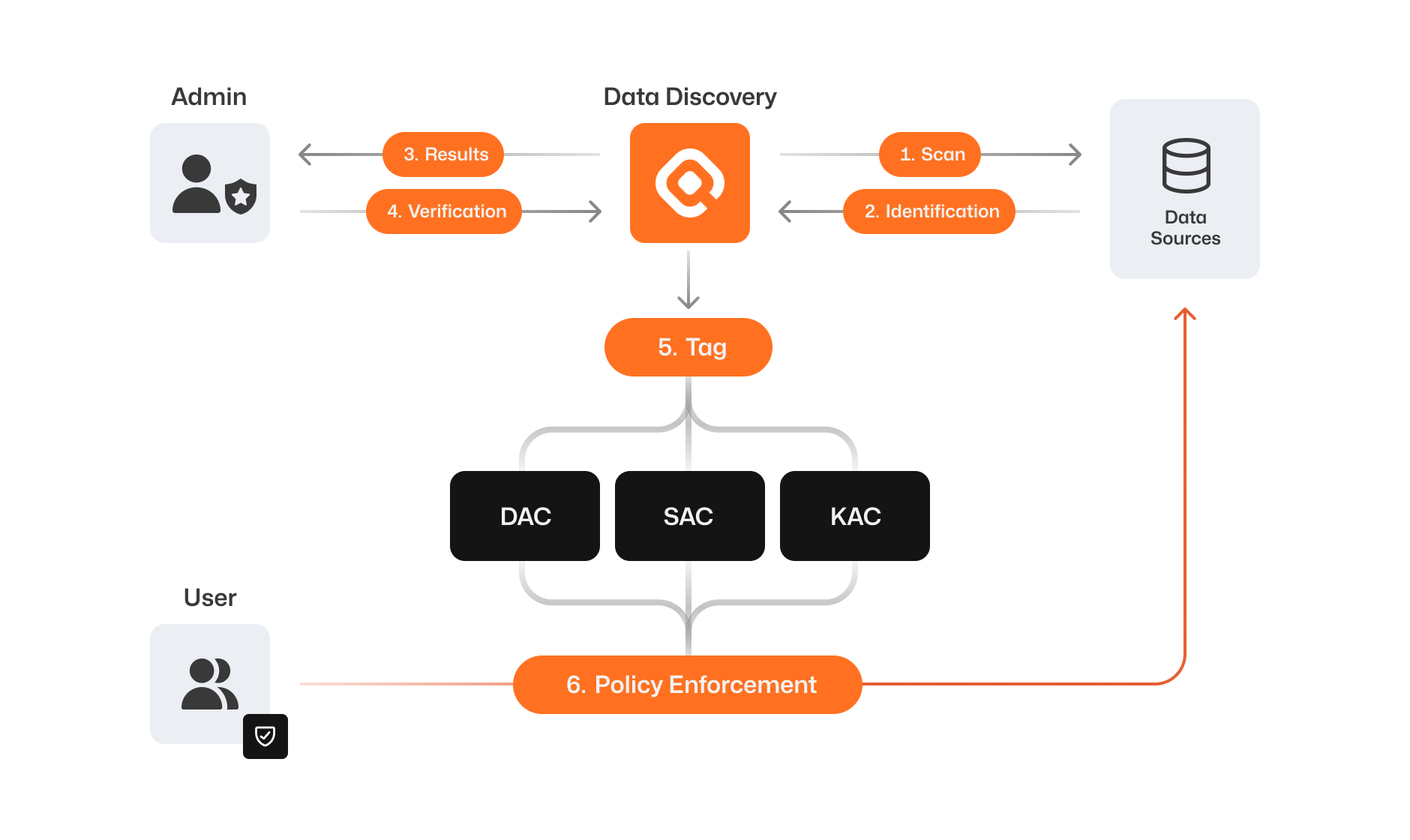
How AIDD Works
As organizations grow, the volume and variety of data they produce and use also increase. Managing this data can become a significant burden. Identifying the presence of sensitive information across complex and diverse data sources is crucial from a security perspective. Therefore, sensitive information within an organization should be managed as follows:
Identify Sensitive Information Within the Organization: Administrators must first recognize what types of sensitive information exist within the organization.
Automated Identification: Sensitive information should be automatically identified, rather than having administrators manually inspect each data source.
Regular Management: Organizational data is dynamic, so it requires regular checks at predetermined intervals.
Mapping to Relevant Types and Compliance: Identified sensitive information should be categorized by type and easily mapped to associated regulations, allowing administrators to plan protection strategies accordingly.
Access Control for Discovered Sensitive Information: Discovered sensitive information must be access-controlled, with necessary security measures such as masking or encryption applied.
Periodic Audits and Monitoring: Regular audits and monitoring of how sensitive information is used can help develop new strategies to counter various security threats.
Managing Sensitive Information with QueryPie Data Discovery
QueryPie’s Data Discovery regularly or manually scans organizational data sources, based on the user's preference.
Automatically identifies existing sensitive information and assigns categorized tags.
Identified sensitive information is automatically mapped to relevant types and associated regulations, making it easy to review.
Administrators evaluate the results of the scan to determine if the automatically detected sensitive information includes any false positives and confirm the presence of sensitive data in the relevant data sources.
Once verified by the administrator, the confirmed sensitive information is tagged in its respective path and is finally reflected in the inventory.
The finalized sensitive information can be easily identified through the dashboard.
Differences Between General Data Discovery and Secure Data Discovery
Purpose
General data discovery aims to derive business insights through data analysis, aiding in decision-making.
Secure data discovery focuses on protecting data, preventing security threats, and ensuring regulatory compliance.
Classification Criteria
General data discovery categorizes data based on ease of analysis or business objectives.
Secure data discovery classifies data according to sensitivity and security needs.
Technologies Used
General data discovery typically uses data analysis and visualization tools.
Secure data discovery employs data classification tools, data loss prevention (DLP) solutions, and data access control systems.
Utilization of Results
Results from general data discovery are used in business strategy development, marketing, and operational optimization.
Results from secure data discovery are used to strengthen security policies, respond to threats, and implement data protection measures.